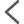闲来无事又想着玩玩Ai,然后想学习下爬虫。
记录一下跟ai沟通的写的一个简单爬虫。
向Ai提需求(变身甲方baba 哈哈)
提取需求之前,我们自己要有想法,该怎么下载这些图片,正常是不是鼠标选择图片点击右键下载。那这样不得累死。既然是自动化,那我们右键复制图片链接,打开无痕浏览,打开。
ok图片显示出来了,证明图片链接是可以直接下载的。这不思路就来了嘛。
①先获取到所有的图片链接。
②写代码批量自动下载保存。
PS:就这么简单的思路,哈哈。
那么怎么获取到所有的图片链接呢?打开要爬的网址,F12定位,详细的XPath信息不就来了,右键复制XPath。
查看网址信息,请求头,User-Agent、Cookie等信息。保存。
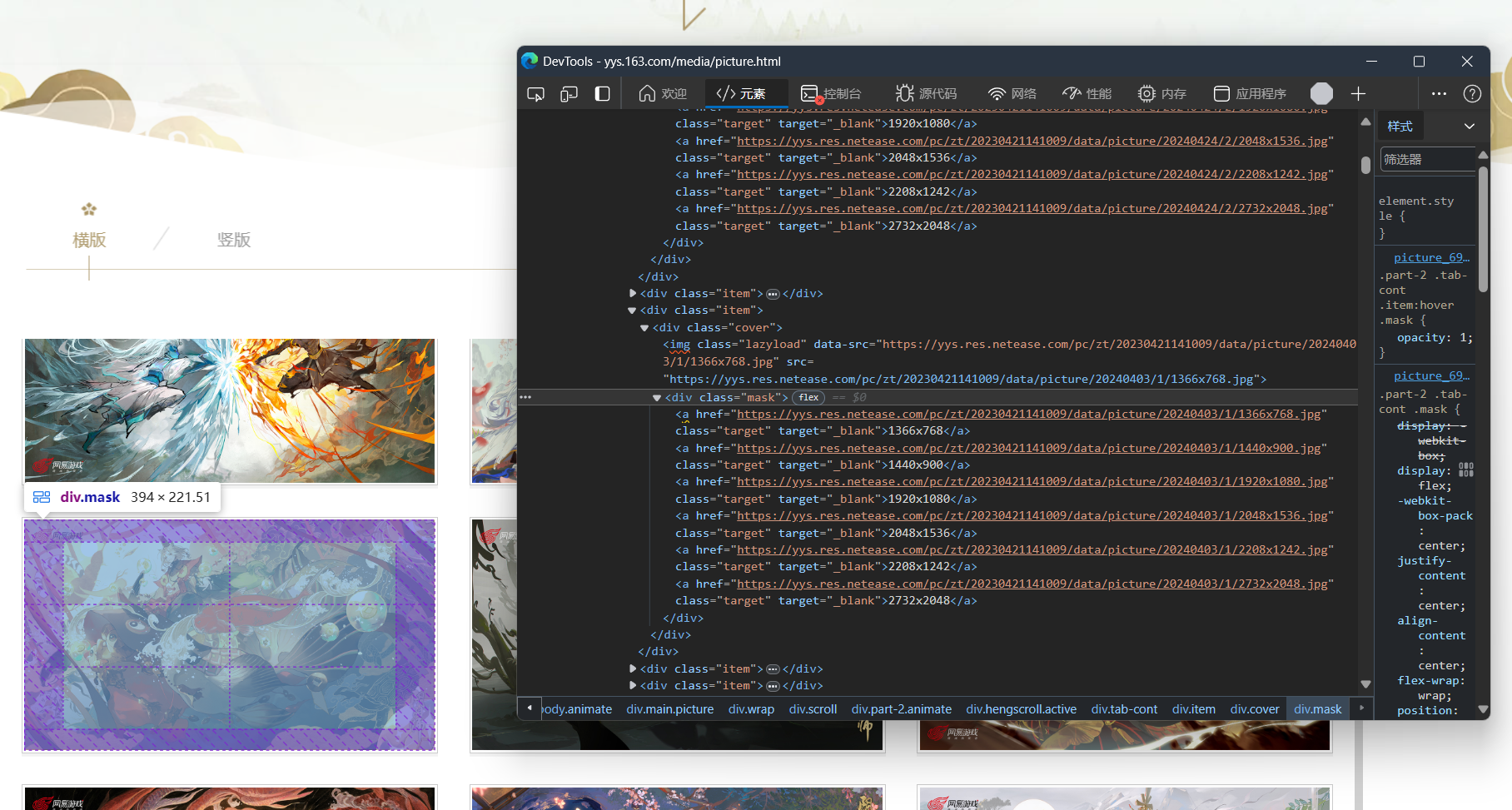
然后把得到的信息整合一下,编辑需求提交给乙方(chatGPT)。
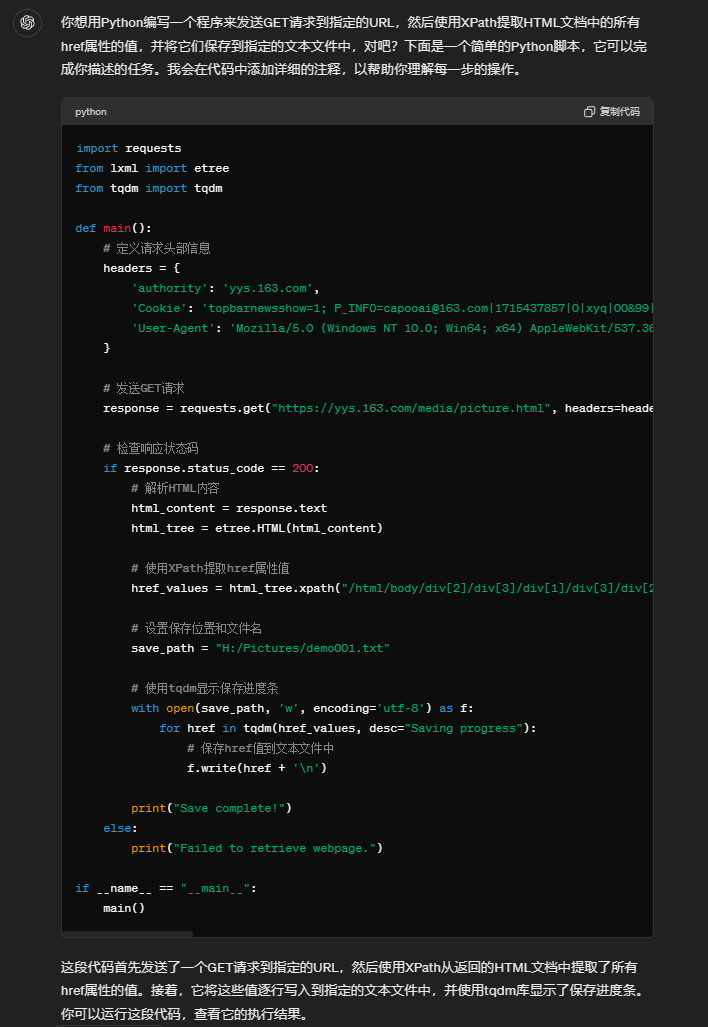
不得不说AI效率就是高,分分钟出代码。但是我测试一下没用,运行不报错,也无法获取 ,经过我几轮的返回日志,发现XPath表达式写错了。改完之后就运行成功。
ai是这样的,每次都是一堆bug,必须得有一点基础,不然都知道为什么没用。
最终得到如下代码:
import requests
from lxml import etree
from tqdm import tqdm
def main():
headers = {
'authority': 'yys.163.com',
'Cookie': 'topbarnewsshow=1; P_INFO=capooai@163.com|1715437857|0|xyq|00&99|null&null&null#jix&360100#10#0|&0||capooai@163.com; Qs_lvt_382223=1715826885; Qs_pv_382223=3122144086163182600; _ga=GA1.1.76648450.1715826886; _ga_C6TGHFPQ1H=GS1.1.1715826885.1.0.1715827356.0.0.0; _nietop_foot=%u9634%u9633%u5E08%7Cyys.163.com; topbarnewsshow=1; timing_user_id=time_QFzBHpwgxy',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
response = requests.get("https://yys.163.com/media/picture.html", headers=headers)
if response.status_code == 200:
html_content = response.text
html_tree = etree.HTML(html_content)
href_values = html_tree.xpath("/html/body/div[2]/div[3]/div[1]/div[3]/div[2]/div/div[*]/div/div/a/@href")
save_path = "H:/Pictures/demo001.txt"
with open(save_path, 'w', encoding='utf-8') as f:
for href in tqdm(href_values, desc="Saving progress"):
f.write(href + '\n')
print("Save complete!")
else:
print("Failed to retrieve webpage.")
if __name__ == "__main__":
main()
import os
import requests
from tqdm import tqdm
import threading
def extract_size_info(url):
# 提取文件名部分
filename = url.split('/')[-1]
# 提取图片大小信息
size_info = filename.split('.')[0]
return size_info
def download_image(url, folder_path, filename):
# 获取已下载文件数量
files_in_folder = os.listdir(folder_path)
num_files = len(files_in_folder)
# 拼接保存路径,并添加编号
save_path = os.path.join(folder_path, f"{num_files+1:05d}_{filename}")
# 下载图片并保存
response = requests.get(url, stream=True)
total_size = int(response.headers.get('content-length', 0))
block_size = 1024
progress_bar = tqdm(total=total_size, unit='B', unit_scale=True, desc=filename, leave=False)
with open(save_path, 'wb') as f:
for data in response.iter_content(block_size):
progress_bar.update(len(data))
f.write(data)
progress_bar.close()
def download_images(image_urls, base_path, num_threads):
# 创建总进度条
total_progress_bar = tqdm(total=len(image_urls), desc="下载进度")
# 创建下载线程列表
threads = []
# 遍历图片链接列表
for url in image_urls:
# 提取图片大小信息
size_info = extract_size_info(url)
# 创建文件夹路径
folder_path = os.path.join(base_path, size_info)
# 如果文件夹不存在,则创建
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 提取文件名
filename = url.split('/')[-1]
# 创建下载线程并启动
thread = threading.Thread(target=download_image, args=(url, folder_path, filename))
thread.start()
threads.append(thread)
# 更新总进度条
total_progress_bar.update(1)
# 控制线程数量在5到10之间
if len(threads) >= num_threads:
for t in threads:
t.join()
threads = []
# 等待剩余线程结束
for t in threads:
t.join()
# 关闭总进度条
total_progress_bar.close()
print("下载完成!")
def main():
# 读取图片链接列表
image_urls = []
with open("H:/Pictures/demo001.txt", "r", encoding="utf-8") as file:
image_urls = file.readlines()
# 去除换行符
image_urls = [url.strip() for url in image_urls]
# 基础保存路径
base_path = "H:/Pictures/yys/side"
# 线程数量限制在5到10之间
num_threads = min(max(len(image_urls) // 10, 5), 10)
# 调用下载函数
download_images(image_urls, base_path, num_threads)
if __name__ == "__main__":
main()
请求资源或报告无效资源,请点击[反馈中心]